A few weeks back I switched from Raindrop to Readwise for my reading, highlights, and related notes. The main reason for
switching was the Kindle integration, but part of my criteria is an API integration where I can automatically collect +
archive the data into my personal cloud. It ended up being a bit of a learning curve, so below are notes for anyone
who might be interested in doing the same:
The Readwise umbrella has two apps: Readwise and Reader. Readwise focuses on highlights + reviewing highlights, whereas
Reader is a web bookmarking + highlighting tool that’s more akin to Raindrop. The APIs are separate, with their own
docs + internal concepts: Readwise APIReader API
Consistent with the apps, the Readwise API focuses on “Highlights” + “Books” and the Reader API centers around
“Documents” which can be links, highlights, and notes.
Readwise has many integrations, including with Reader. So a saved link + highlights in Reader will also show up in
Readwise (despite the “book”-centric terminology). Saved links without highlights will not show up in Readwise.
Somewhat annoyingly, the two use completely different id spaces. e.g. if I have “17 ChatGPT Use Cases”, it might have
user_book_id123 in Readwise but document_idasdf in Reader. There is an indirect one-way lookup between the
two: the Readwise record contains a unique_url field that has the format https://read.readwise.io/read/asdf. Other
than that, the only way to tell if a Reader item is “the same” as a Readwise item is via other attributes like article
title or url.
Another idiosyncrasy: highlight entries from the Readwise API contain location information, i.e. “where in an article”
or “what page in the book” the highlight came from. The Reader API does not have this information – even for items
generated by the Reader app.
Finally: the Reader API recently added a withHtmlContent which returns a document’s scraped HTML from Reader.
Readwise has no equivalent of this field.
So in my case, where I want the maximum information around my reading + highlights + notes, I have to sort of stitch
together the two APIs. Roughly:
Pull non-highlight items that get saved in Reader so I have the most complete list of links / articles / videos / etc.
Readwise is the source of truth for highlights + metadata. It contains the most info including location information.
When an item gets saved in reader and then highlighted later (i.e. in between archival script runs), use the
unique_url above to link the original Reader item to the Readwise item for highlight information.
Despite some workarounds, this API integration has been working alright so far. The products themselves are also pretty
top notch. Now I just have to go and backfill all the Reader html_content for my items from before they introduced
it…
One of the annoying things about running the personal cloud is managing secrets (API keys, google creds, etc) for
the bits that run locally on my laptop.
So far I’ve just been shuffling these creds around local-only env files tied to a couple of start scripts. It’s kind of
a pain cause the files can’t be shared or committed to GitHub for obvious reasons so I have to walk on glass every time
I touch them. And lord help if I accidentally delete one of the files or get them mixed up somehow.
Last week I finally got tired of the nonsense and automated it via 1Pass. Apparently they have a nifty
command line package that makes this pretty easy. (And if you’re not running
1Pass or some password manager by now… What are you doing??)
First, set up a new env file with 1pass urls. local_apps is a separate vault I keep local dev secrets in, just for
organization’s sake.
op run --env-file="./.deploy.env" -- ./bin/server start
Now the local app secrets have all the usual 1Pass convenience: history tracking, sharing between machines, encryption
at rest, etc. Plus I can (finally!) commit the 1pass env files to GitHub as part of the build.
As part of building my personal cloud, I wanted to back up my browser history. This is useful for info mining and search
purposes, but also because Brave (or Chromium?) starts dropping data after 90 days. Who knew. The 90 day limit is
hard-coded, so data loss is unavoidable without an export.
So first, the location. On Macs this is ~/Library/Application Support/BraveSoftware/Brave-Browser/[Default || Profile N]/History/brave_history.sqlite.
For chrome, the location is similar ~/Library/Application Support/BraveSoftware/Google/Chrome/[Default || Profile N]/History.
The history is kept in a sqlite database, either brave_history.sqlite or History. It’s usually locked while the browser
process is running, but a quick hack is to make a copy of the file to a temp location to make it read/write-able.
From there, the usual sqlite exploration tools work. I recommend litecli, by the same folks behind the excellent pgcli.
An example query to extract browsing history into denormalized rows to throw into a csv or what have you:
select v.id, v.visit_time, u.url as url, u.title as url_titlefrom visits vinner join urls u on v.url = u.id;
A quick note on visit_time: it is not milliseconds from unix epoch, as I had initially expected. It’s actually
microseconds from the win32 epoch, which is Jan 1 1601 00:00:00 UTC. To get to unix epoch millis, subtract
11644473600000000 from visit_time and divide by 1000.
Over the years I’ve noticed people seem to have two fundamental orientations towards goals: aspiration-first and
reality-first.
Aspiration-first thinking starts with an external or motivational stance. For example: “I need to lose 20 lb before
summer to fit into my beach clothes / reach a certain BMI / etc” Or in business: “We need $1MM ARR this year because
that’s the benchmark for companies of our stage.” From there, achievement is throwing stuff against the wall till
something hits the right trajectory.
Reality-first thinking starts with understanding the reality of a situation or system and works from there. For
example: “Studies suggest sustainable weight loss is 300-500kcal deficit per day, so I should lose Xlb by summer. But
also I like eating, so maybe (X - 5)lb is a better goal.” Or: “Historically our revenue growth has been X per month,
but our sales process isn’t as efficient as it could be, so with some tweaks we should be able to get it to (120% of X)
per month.”
This rhymes a bit with “top-down” vs “bottom-up,” but I don’t think they are the same. If an experienced CEO says “we
should get our revenue up 15% within the next 6 months,” that’s top-down but could be reality-first because that goal is
informed by a long career in similar companies where they have increased revenue by 15% in 6 months. Likewise, a
bottom-up goal might be “reduce server costs 20%” in service of reducing burn rate… But that 20% number could be
completely aspirational with no basis in reality.
Both approaches have their pro’s and con’s. Reality-first has the obvious advantage of being easier to reason about:
either execution is off, or an assumption about reality was wrong. In that way, the lines of accountability are
clearer. There’s no “shucks we tried, but…” However, sometimes a situation is so uncertain that you have no choice
but to be aspirational. (Though I’d argue that “setting goals” is less useful then, vs taking a stance of “learning
about reality.”) Lastly: the “big hairy audacious” goals that are popular in management literature are aspirational by
definition, so they may be necessary for certain types of work.
To the surprise of absolutely nobody, I favor the reality-first approach as a developer-slash-systems-person. That
might mean my goals are not as big, hairy, and audacious as they could be but… I can live with that :)
Yesterday I was editing a photo on my phone when I got hit with a prompt: $3.99/mo for premium features! It really
feels like every software company and their mother wants to move to a subscription model these days. From a business
standpoint, I get it: recurring revenue brings warm fuzzy feelings and is easier to sell to financiers. But as a
customer it’s incredibly annoying when the pricing doesn’t match the value.
In this case, my thoughts ran through some usual tracks: Why should I pay a monthly fee for a photo editing app? They
don’t have any server or maintenance costs. All the work is done on my phone, and the photos live on my storage. And
it’s not like the software changes that often, only so many things you can do to a photo. But:
it’s not like the software changes that often
… Is that actually true? Apple and Google are on a pretty regular (cough gratuitous) release cadence with their
phones and corresponding OS SDKs. SDK updates always come with breaking changes, so developers either have to update or
leave it broken (through no fault of theirs) and face a horde of angry existing users. Even absent any new features,
that naturally causes churn and maintenance costs. Is it enough to justify a monthly fee? I’m honestly not sure.
This set of incentives has a second order effect: software bloat. If a developer needs to update the software and they
need to charge users for it, then they might as well make it more palatable by adding new features. Thus even the
smallest apps are doomed to bloat and an endless grind if they want to be sustainable to their makers. Conversely, a
certain class of apps will never get made – at least, not without the acceptance that their useful life is completely at
the big app stores’ whims.
It’s pretty annoying that this is the state of software and I don’t have any suggestions for fixing it. Maybe just:
don’t hate the player, hate the game?
Lately we’ve been thinking about fundraising at work. We’ve built a good product and a business with gathering momentum
and positive unit economics. Even without a raise we’re likely to be in the black in a reasonable amount of time –
knock on wood – or as Silicon Valley likes to say, default alive.
The knee-jerk response for early stage SV-style startups is “of course you should raise, you can grow faster!” But
another way to phrase “growth opportunity” is “upside risk,” and once you say “upside risk” the next natural thought is
“downside risk.”
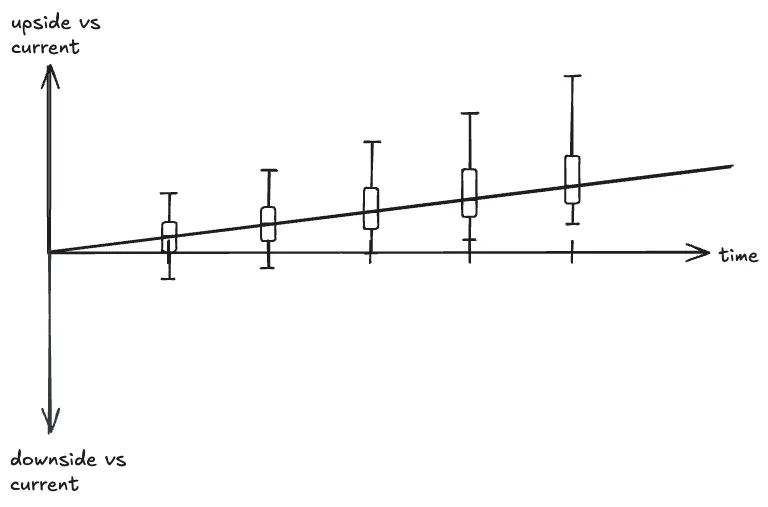
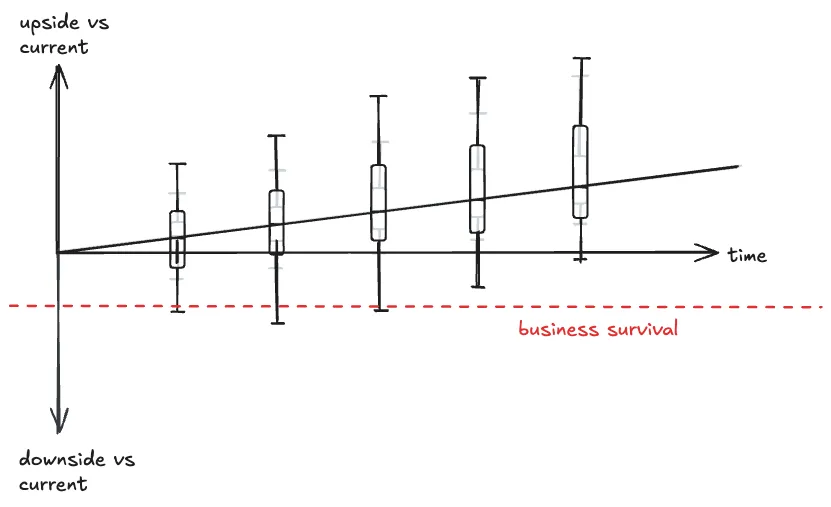
So here’s something I’ve been musing over. The outcome distribution of a good business with some level of history
probably looks roughly like this:
(Defining “box plot” is outside the scope of this post, please see the wiki page :))
There’s always some variation because that’s life and the universe, but generally if it’s a decent business it will grow
at some minimum rate above the overall market. If it’s a good/great business, the distribution of downside will get
lower from stabilization of operations and upside will get higher from natural expansion and moat-building. Over the
long term, it’s likely to end up ahead of where it was.
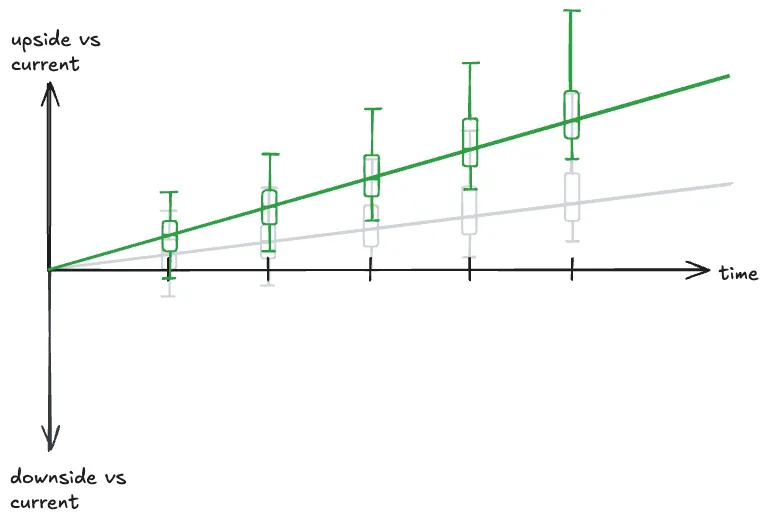
It’s tempting to think of executing a “growth opportunity” as something like this:
The median outcome gets nudged upwards but the level of variance stays the same. Except that’s a free lunch, and
there’s no such thing as a free lunch. Any initiative strong enough to introduce upside risk will naturally introduce
downside risk. Spinning up a new team incurs additional costs, bringing on investors increases potential for strategic
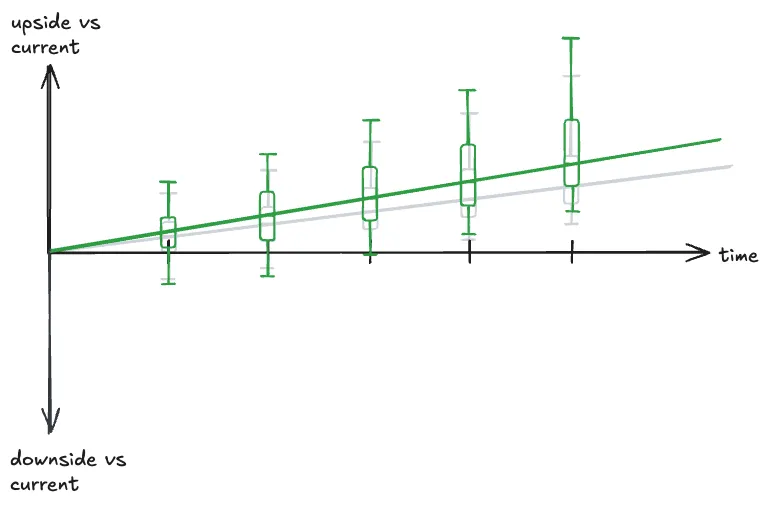
misalignment, etc etc. Realistically, a good growth case probably looks more like this:
There’s larger downside risk in the short term because of disruption from the changes, but the downside is asymmetric.
The more asymmetric your bet, the more upside you get in exchange. Over time the business adapts and captures
additional opportunity, it ends better than the base case, and Bob’s your uncle.
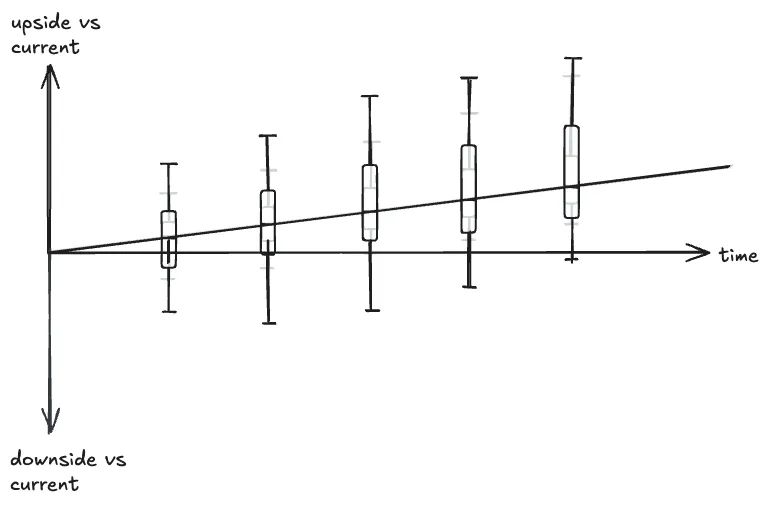
But it’s also easy to accidentally do this with your changes:
… AKA the “yolo bet.” The median stays the same, but you’ve blown out both ends of your risk distribution. This is a
bet that’s ~usually not a great one, because there’s one line missing in the charts thus far:
Most of the time, the ability to absorb downside is limited: at some point, it will just kill the company.
Nevertheless, there are valid reasons to make the yolo bet. The obvious one is if the business is actually down-trending
and you need a Hail Mary. Or perhaps you subscribe to the extreme end of the Silicon Valley ethos: feed it to see if
it’s a unicorn, and if it’s not then better to fail fast and move on with your search.
But even in those cases, I think it’s best to go in eyes open and fully aware of the bet being made.
I first saw “zero-based budgeting” in some leisurely weekend reading on private equity firms (I know, party animal
comin’ through). The idea is to start each annual budgeting process “from zero” and justify all expenses from scratch
instead of anchoring on existing spend. “How much should we spend on X,” instead of “cut 5% off X this year”
This is a useful framework for other contexts:
Every day you stay at a job is a decision to take that job, knowing what you know that day.
Every day you hold an investment position is a decision to buy on that day’s price and fundamentals.
Every day you spend in a relationship, friendship, partnership is a decision to… you get the idea.
Of course, it’s not perfect. Real life has pesky things like transaction costs, but that’s entirely the point. Starting
from zero is an offset against complacency and over-indexing on sunk costs.
I see edutainment as preparation for learning: it’s a powerful explorative tool that can provide ideas and motivation
to learn. And yet, it’s also not learning itself, in the same way as buying running shoes is not running. Within this
framework, “mindless” browsing online can be transformed into scouting for learning opportunities.
The process takes a lot of time and effort, which means it’s not something I can afford to do with every piece of
content I find online. Most of the time I trash the links I find, upon further review. Sometimes they end up in my
learning wish list.
The core idea is trying my best to not kid myself: when my engagement with a piece of content is active and effortful
then it’s learning, when it’s passive it’s entertainment. When I create I learn. When I consume I just relax.
As a part work on an old project, I used sqlite native fts for an MVP full text
search. The setup was interesting + ~mostly worked, so it deserves a quick walkthrough.
index + trigger setup
For the this walkthrough, let’s say I have a table bookmarks with a title and a description field. First step is
setting up the index:
The content option tells sqlite that this is an external content table
— that is, the full bookmark content lives outside of fts_bookmarks. I chose this setup because 1) bookmarks
contains other information that doesn’t need full text search; 2) I already have a bookmarks table, so duplicating all
fields is a waste of space; 3) I still want some fields e.g. title to be easily accessible without joining.
The downside is that sqlite leaves it to the user to ensure that the index is up to date with the source content. This
is relatively straightforward with triggers, though a bit verbose:
create trigger bookmarks_ai after insert on bookmarks begin insert into fts_bookmarks(rowid, title, description) values (new.id, new.title, new.description);end;create trigger bookmarks_ad after delete on bookmarks begin insert into fts_bookmarks(fts_bookmarks, rowid, title, description) values('delete', old.id, old.title, old.description);end;create trigger bookmarks_au after update on bookmarks begin insert into fts_bookmarks(fts_bookmarks, rowid, title, description) values('delete', old.id, old.title, old.description); insert into fts_bookmarks(rowid, title, description) values (new.id, new.title, new.description);end;
Unfortunately, sqlite doesn’t offer first-class update or delete operations on external FTS tables. Instead, you
have to insert a ‘delete’ command with the exact current values in order to delete or update a given row. NB inserting a
‘delete’ with the wrong values can bork the entire index. The reasoning given in the docs
makes sense, but still seems like a leaky abstraction and an annoying gotcha.
doing search
After all the pomp and circumstance, the index can be used like so:
select rowid from fts_bookmarks where fts_bookmarks match 'some title';
With light ecto wrapping:
select rowid as id, rankfrom fts_bookmarkswhere fts_bookmarks match 'some title'order by rank;
It’s worth noting that sqlite has its own query syntax +
tokenization which is exposed in its unadulterated form to the caller. This can lead to some weird edge cases, e.g.
query_string = 'abc.d' will fail because of the naked period.
is it good?
I stand by my characterization from the intro: sqlite fts5 is interesting and ~mostly works. Would I reach for it
again? Sure, if I’m stuck in sqlite and want to write minimum app code :) There are enough sharp edges that I wouldn’t
use it as-is for anything end user facing, but at the same time it’s a nice addition to the toolkit for the
quick-and-dirty use cases.
Just finished reading Tomorrow, and Tomorrow, and Tomorrow
this past week and it’s the best fiction I’ve read in recent memory. Certainly the best realistic-ish fiction I’ve read
in years. Whether it’s the close demographic match (Asian immigrant, grew up with the internet, spent a lot of
childhood in virtual game worlds…), the fresh variation of style and framing devices, or quippy lines like “To return
to the city of one’s birth always felt like retreat,” this one just hit.
It’s not perfect book by any means. But chances are if you’re on this blog and still reading for whatever reason,
you’ll probably like it too. In the meantime guess I’m gonna read AJ Fikry just in time for the movie.
For a while now I’ve felt like my zsh has been starting up more and more slowly. It’s one of those small annoyances that
builds up over time, especially if you pop a lot of shells via e.g. tmux and have to wait more than “One Mississippi” to
do anything. This week I finally got annoyed enough to do something about it.
before
Step one is to figure out exactly how slow and why. First I timed the init:
$ time zsh -i -c exit0.71s user 0.58s system 52% cpu 2.479 total`
… Two and a half seconds?? Ouch.
Next was to figure out what was causing the slowness via the profiler:
# in .zshrc...zmodload zsh/zprof# rest of config filezprof
This gets zsh to print out a breakdown of resource use for everything in .zshrc. The output looks something like:
tl;dr - the first 25 or so lines for me were dominated by nvm and rvm. Somehow not surprised.
nvm
nvm apparently takes forever for a variety of reasons, so the best course is to only use it when needed. There are
manual solutions out there, but I decided to lean into oh-my-zsh and just use the plugin’s built-in lazy functionality.
After removing the manual nvm install:
# in .zshrc / configexport NVM_LAZY=1plugins=(nvm)
rvm
rvm is mostly around as cruft I had picked up over the ages. I don’t use ruby often (or at all) these days, so I just
went ahead and removed it. However, there are othersolutions for folks who still need it + want lazy loading.
after
After the above, the time went down to about:
time zsh -i -c exit 0.23s user 0.10s system 101% cpu 0.332 total
Repeated runs showed it mostly starting in .3 - .5 sec. Pretty good, but still plenty of room for improvement.
Roam Research is the darling of the latest wave of knowledge management / note-taking apps.
I’ve been using it for about two months now. tl;dr - Roam delivers on its promise of networked thought and the features
around bidirectional linking are extremely well-executed. However it does still have non-trivial downsides, for example
the mobile experience. So I’m not a card-carrying member of the #roamcult just yet but I will continue to use it, at
least over the short-to-mid term.
😄
The affordances for bidirectional linking are super slick. A link can be created at any time by enclosing it in
double brackets, e.g. [[chicken]]. This ease makes it ridiculously easy to link pages of notes together, which
delivers on the promise of “networked thought.”
The features around links are worth emphasizing. The backlinks are automatically generated, which saves a bunch of
work + friction, and the backlink display strikes a good balance for showing context around the link.
Once the page is fully loaded up, everything is pretty snappy. I tend to get annoyed at the “let’s ease all the
transitions and stick animations everywhere” brand of user-friendliness, and there definitely is not any of that here.
Power user features abound. Block queries and embedding
javascript stand out here — although the latter definitely makes me nervous for all sorts
of reasons.
😕
UX is still pretty rough in some spots. The initial loading screen is mildly annoying, and I personally find the
sidebar functionality clunky and unintuitive. However, the primary experience around links + note management is good
enough that I’m willing to put up with the rest.
Quotes are conspicuously missing from the markdown support. I have no idea why.
I find that my Instapaper queue is getting longer because I’ll start reading on my phone and think, “oh right I should
note this in Roam.” Keeping articles around until I can revisit on the computer is just enough friction for things
to start getting backed up. I haven’t decided whether this is a good thing (forcing delination between “productive,
deserves notes” reading vs entertainment) or a bad thing (friction is a habit killer, reading less is no good).
🙁
The roughest UX spots are still around mobile. I wouldn’t say the experience is outright terrible, but the things
that I can work around in the browser definitely become a lot more annoying on the phone. Reading is OK-to-meh,
writing is moderately annoying, and capture is only just barely there.
*tinfoil hat on* Roam is “in the cloud,” which means all data lives on their servers. Normally I’m not a huge
stickler for this, but any app functioning as a second brain is bound to contain sensitive information such as
personal information, contacts’ personal information, “opinions I would definitely not put on twitter,” etc. It would
be great to see a self-hosted option, or more work around end-to-end encryption.
IO.inspect is great for println debugging, and generally “does the right thing” with just about any input you throw at
it. Up until recently, I would use it in a way that looked something like this:
… which is mostly fine, but the extra IO.puts is still kind of bothersome — especially if I have multiple points in
the pipeline that I’m inspecting. But then I learned about the :label option:
:label saves an extra line and makes things way nicer for printing multiple steps in a pipeline. Neat. This kind of
thing seems petty, but it really does add up over time and make elixir a shockingly pleasant language to use.
One sentiment I see from people coming from dynamically typed languages (python, ruby) or even Java and C is a general
dismissiveness about static typing and compilers. At best, the sentiment is “Oh, well it makes sure my input is an Int,
or a Float, or a Bool… That’s cool I guess, but I can do that with TDD”. At worst, static typing is seen as
something to fight against — shackles that limit our creativity and bar us from what we really want to do and the
beautiful programs that we could write if only the type-checker got out of our way.
Personally, I think of the type-checker (and by extension the compiler, really) not only as a free suite of rigorous
tests built from first principles, but as a friend that is nice enough to correct me, the silly human, when I think I’m
making sense but I’m really not. Sure, sometimes that friend is a bit dense (ahem Java, ahem) and can’t quite
understand what I’m trying to say, but in the case of a language like Scala I find that the compiler is right more often
than not. In fact, I had a whole giant wall of text geared up to talk about the value in using Option over null, in
using Either instead of exceptions, in capturing values without using Stringly-Typed data… But then Li Haoyi beat
me to it with another addition to his wonderful Strategic Scala Style series: Practical Type Safety.
I highly recommend reading it (and the rest of the Strategic Scala Style series) before coming back.
Still here? That post covers a lot of what I wanted to say, but I wanted to put some extra emphasis on one particular
topic…
ADTs (!!!)
ADTs (Algebraic Data Types) are so, so good. You can take a lot of features away in Scala and I could probably get by,
but ADTs — Or at least, the closest Scala approximation — are on the short list that you’d have to pry out of my cold
dead hands… Along with higher order functions and pattern matching, probably.
So, a quick review… What are Algebraic Data Types? ADTs are so named because their structure can be described in two
operations: Product, and Sum.
Product Types
Product types are present in one form or another in the vast majority of mainstream programming languages. People may
know it as a struct in C, or a record, or a tuple, or a case class in Scala. It’s essentially a way of mashing
multiple types together into one type. The reason it is called a product type is because the cardinality of the type
(i.e., the set of all possible values for it), is the product of the cardinality of the type’s constituents. Some quick
examples:
// Has 2 possible values: A(true), A(false)case class A(b: Boolean)// has (2 * 2 = 4) possible values: AA(true, true), AA(true, false), AA(false, true), AA(false, false)case class AA(b1: Boolean, b2: Boolean)
Sum Types
Where product types express “this and that and the other thing”, sum types (also commonly known as union types)
express “this or that or the other thing”. Sum types are so named because the cardinality of a sum type is the
sum of the cardinality of the type’s consituents. Unfortunately in Scala 2.x, there isn’t direct support for sum types,
but they can be roughly approximated with sealed trait. Some examples:
// Probably not how any of this is implemented in the actual standard lib but you get the idea :)sealed trait Booleanfinal case object True extends Booleanfinal case object False extends Booleansealed trait Option[T]final case class Some(x: T) extends Option[T]final case class None extends Option[_]sealed trait Either[A, B]final case class Left[A, B](a: A) extends Either[A, B]final case class Right[A, B](b: B) extends Either[A, B]
One cheerful note is that proper union type support was announced for Dotty at ScalaDays 2016, so hurrah! *confetti*
So What?
At first glance, ADTs might seem simplistic — kinda like fancied up named tuples. But they are deceptively powerful,
because combining them effectively allows you to encode invariants about your program’s logic and state in the
type system, and therefore leverage the compiler to keep you from violating those invariants and writing buggy software.
Which sounds like a bunch of abstract nonsense, so it’s time for a concrete example!
Modeling Real Life: Wrangling User Lists
Working in the marketing space, it is very common to deal with lists of users. It can be a list of users from a mailing list, a list
of website visitors, or a list of people who have downloaded your white paper. In any case, it is a list of users that you
have in your possession, and you want to follow them around the internet and serve them ads. Such a list of users might
have attributes like an id and a human-readable name. Since most folks aren’t in the business of building exchanges,
it might also have a downstream platform to target (e.g., AdWords, or Facebook). It might also have some different
states that keep track of whether the list’s meta-data has been sent to the downstream platform, or whether it’s been
archived or soft-deleted and when that state transition happened.
So one reasonable implementation at a data structure for such a user list might look something like:
sealed trait ListStatusfinal case object Pending extends ListStatusfinal case object Active extends ListStatusfinal case object Archived extends ListStatussealed trait Platformfinal case object Facebook extends Platform // And so on and so forthcase class UserList( id: Long, name: String, platform: Platform, status: ListStatus, createdTime: Long, archivedTime: Option[Long], downstreamId: Option[String] // i.e., a "foreign key" to the list on the downstream platform)
At first glance, this seems like pretty reasonable code. The various states and platforms are enumerated, and it seems
to carry all the information we want with decent naming and so on. At the very least it’s better than carting around a
tab-separated string, or something like val list: (Long, String, ListStatus, Long, Option[Long], Option[String]).
But there’s still something a bit off here. In particular, look around the optional fields. With this current model,
it is possible to construct an internally inconsistent list:
val list = UserList( id = 1, name = "website visitors", platform = Facebook, status = Active, createdTime = System.currentTimeMillis, archivedTime = None, downstreamId = None // Wait, what?)
The example above is internally inconsistent because the list’s active status indicates that it should be onboarded to
the downstream platform, but for some reason we do not have a downstream id. There are other “weird” cases like this
that are possible but do not make sense semantically — for example, archivedTime = Some(1) with status = Pending.
This data structure is almost trivially simple, but there area already a good number of things that can go wrong,
especially once we take outside input and possibly complex business logic into account. And here there’s nothing
stopping us from constructing these degenerate cases other than our ability to keep everything in our heads (spotty even
at the best of times) and read the code really really carefully every time we work with this particular data structure
(good luck).
Another point to consider is what this does to the code that works with the data:
// Send users from our list to downstream platform so we can serve them adsdef onboardUsersToList(list: UserList, users: Seq[User]) { list.status match { case Active => { val platformId = list.downstreamId.getOrElse { // this should never happen throw new IllegalStateException("Downstream id not found for active list") } platformClient(list.platform).sendUsers(platformId, users) } case _ => throw new IllegalArgumentException("Cannot onboard users for non-active list") }}
The above code is a conceptually simple method that takes users from our list and sends them to a downstream platform,
e.g. Facebook. It technically does what we want, but there is a lot of clutter introduced by the management of the
status. The block under list.downstreamId.getOrElse is particularly bad, since it basically amounts to saying “well
we don’t think we’re wrong, but we technically could be wrong, so we have to sprinkle this boilerplate-ish error
handling into our business logic”. Apparently, this sort of thing is
notthatuncommon.
One possible remedy is to refactor UserList to encode some of the constraints into the type:
final case class UserListMetadata(id: Long, name: String, platform: Platform, createdTime: Long)sealed trait UserList { metadata: UserListMetadata }final case class PendingList(metadata: UserListMetadata) extends UserListfinal case class ActiveList(metadata: UserListMetadata, downstreamId: String) extends UserListfinal case class ArchivedList(metadata: UserListMetadata, archivedTime: Long) extends UserList
At this point, one might protest, “That just makes you push the status validation somewhere else! The first
implementation was just bad practice, you could easily have written this simple version with the old type by refactoring
to def onboardUsersToList(downstreamId: String, users: Seq[User]).” Yes, this is perfectly true. The validation
still has to take place somewhere since the code will presumably be interacting with the outside world. The
difference here is that the former implementation can only enforce cleanliness and correctness with malleable things
like documentation and best practice guidelines, whereas the latter implementation enforces it by simply refusing to
compile until you fix it. The latter implementation also reduces the amount of “unforced” errors since it is
impossible to construct an ActiveList object without a downstreamId, whereas it was possible to accidentally create
a UserList(status = Active, downstreamId = None) previously.
Stepping back
Hopefully the above example demonstrated a reasonable real-world case where ADTs can be really useful. ADTs seem really
basic — and in the vast world of type hackery they are only a starting point — but you can do some surprisingly
powerful things with these fundamental building blocks.
There is one last point I want to make. As a professional programmer (i.e., employed by a business to write code that
ostensibly generates some amount of profit), the goal of all this is not to encode the world at the type level. The
goal is to reduce complexity and mental overhead. There are some insane things possible once you go down the rabbit
hole of type hackery — for example, type-level quicksort. This
is all great fun and by no means a bad thing, but at some point it’s important to step back and think, “Right, somebody
else actually has to read, maintain, and modify this code at some point. Maybe this should not go into production.”
This is especially important to keep in mind in a language like Scala, which provides us with plentiful amounts of
power to complicate things and shoot ourselves in the foot if we’re not careful.
Let’s talk about clojure for a bit. Or lisps in general, I guess. A lot of the “kinda joking except not really” quips
that commonly float around on the internet are about the parentheses, as in how there are so many of them. For example,
if you want to take a number x and add one, multiply by two, then add 3, the code might naively look something like
this:
(+ (* (+ x 1) 2) 3)
Or perhaps like this:
(+ 3 (* 2 (+ 1 x)))
Look at the parens! Especially the consecutive 3 closing ones in the second variation. For a sufficiently long chain
of functions, it can get pretty unreadable—especially with multiple arguments and whatnot.
Enter clojure’s thread macro. The thread macro is a macro in the form of (-> x & forms), and it “threads” x through
the forms as the first arg*. Which sounds terribly confusing explained, so an example is probably better here. Take
this snippet using the thread macro:
;; add one, multiply by two, and add three(-> x (+ 1) (* 2) (+ 3))
This desugars into (+ (* (+ x 1) 2) 3), i.e. the first variation of the initial example above. Personally, I find the
macro version much more readable since each call is on its own line, and it seems more expressive of applying a series
of functions to the initial x.
The thread macro is also useful for chaining together collection methods like map. Since clojure doesn’t have
first-class OO support (instead favoring protocols and such), map exists as a regular function that takes the collection
as an arg, instead of as a method on a collection class. So chaining together a bunch of ops on a vector might look
something like…
;; add one to every number and filter for even numbers(->> [1 2 3 4 5 6] (map #(+ 1 %)) (filter even?));; Without the thread macro, would look like:(filter even? (map #(+ 1 %) [1 2 3 4 5 6]))
The only difference is that in this case, ->> was used. ->> is “thread last”, which is like -> (“thread first”), except
it inserts the expression at the end of the form.
This pattern also exists in other languages (especially those that don’t offer first-class OO, which allows fancy
return self type stuff), like Elixir’s pipe |> (in the spirit of the unix pipe) which is what prompted me to spread
the word about this:
# double and add one to each element[1, 2, 3]|> Enum.map(fn x -> x * 2)|> Enum.map(fn x -> x + 1)
The thread macro pattern doesn’t have as much of a place in Scala, since Scala has mechanisms like the collection
library and implicit conversions to help express similar logic in elegant ways. But when I first read up on macros in
lisp, I spent some time scratching my head at the day-to-day practical uses until I found this and had my first
“ohhhhhhhhhhhh” moment. In any case, hope this was mildly interesting!
* - Well technically, as the second item in the form, which is effectively the first arg for functions… But that might
be a bit too lispy.
Bonus
When I published this email to the internal list, it generated some discussion wherein I learned that there are other
neat features of the same sort like doto, and that they’re all just
various derivations of the K combinator. Of course, googling k-combinators led to a pretty
heavy looking wiki page, so I was referred to
http://combinators.info/ , which I have been trying to get through since.